

As artificial intelligence (AI) transforms industries globally, the demand for robust, scalable, and high-performance infrastructure has reached an all-time high. At NVIDIA GTC, we recently unveiled the next generation of Cisco Nexus Hyperfabric options that support AI, which are purpose-built to accelerate innovation and meet the rigorous requirements of modern AI workloads.
What is Cisco Nexus Hyperfabric?
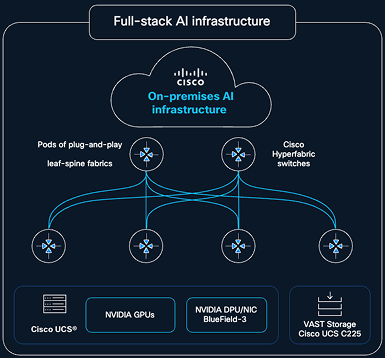
Cisco Nexus Hyperfabric is a cloud-managed controller designed to simplify how organizations build and operate today’s data centers and AI environments. Use it as a full-stack platform for rapid deployment or a flexible bring-your-own approach that lets you tailor compute, GPUs, software, and storage to your needs.
The full-stack AI infrastructure option brings together cloud-managed networking, compute with NVIDIA GPUs, optional storage with VAST Data, and automation into a validated architecture that is NVIDIA Enterprise Reference Architecture (ERA) compliant, removing the complexity of integrating and managing infrastructure across multiple layers. As shown in Figure 1, a centralized cloud control plane streamlines design, deployment, and operations, enabling enterprises and neocloud providers to scale AI workloads faster and move confidently from experimentation to production.
Networking breakthrough: Cisco N9164E with NVIDIA Spectrum-4 with Nexus Hyperfabric
AI workloads are only as effective as the networks connecting compute nodes. Massive parallel processing in AI clusters requires ultra-low latency, high bandwidth, and lossless data transfer. Enter the Cisco N9164E-NS4-O switch, an 800G powerhouse that integrates NVIDIA Spectrum-4 ASICs for state-of-the-art performance.
We’ve integrated the NVIDIA Spectrum-4–based Cisco Nexus 9164E into Cisco Nexus Hyperfabric, further enhancing high-performance AI networking. This addition strengthens the ability of Nexus Hyperfabric to deliver scalable, low-latency connectivity for large-scale AI workloads while supporting NCP-compliant AI infrastructure deployments.
Highlights of the N9164E switch include the following:
- 800G ports: Delivering up to 64 ports of 800G Ethernet in a compact, energy-efficient form factor.
- NVIDIA Spectrum-4 inside: Advanced ASICs designed specifically for AI workloads, enabling Remote Direct Memory Access over Converged Ethernet version 2 (RoCEv2) and enhanced congestion control.
- Deterministic, predictable performance: Critical for distributed AI training, ensuring GPUs across the cluster can communicate at peak efficiency.
- Telemetric insights and automation: Deep visibility and programmability for network operators, simplifying troubleshooting and optimizing resource allocation. This differs from some traditional data center switches, offering the raw network throughput and intelligence needed for the latest AI supercomputing clusters.
Ushering in the next wave of AI infrastructure with Nexus Hyperfabric
To scale AI with confidence, organizations need powerful compute, validated architectures, and deep ecosystem integration. Cisco Nexus Hyperfabric brings these elements together through GPU-accelerated compute, NVIDIA Cloud Partner (NCP)–compliant designs, and a tightly integrated Cisco–NVIDIA stack built for AI at scale.
Compute powerhouse: Cisco UCS 880 with NVIDIA HGX B300 NVL8 GPUs
At the heart of any AI infrastructure lies compute—powerful servers designed to efficiently process massive datasets and complex algorithms. With its new availability with Cisco Nexus Hyperfabric, the Cisco UCS 880 system paired with B300 blades will deliver purpose-built compute designed for demanding AI training and inference workloads, supporting the latest NVIDIA GPUs and high-bandwidth interconnects.
Key features of the Cisco UCS 880 rack server with NVIDIA HGX B300 NVL8 GPUs include:
- High-density, modular design: Scalable to meet growing workload demands without compromising on energy efficiency or footprint.
- Optimized GPU support: Future-proofed for the latest GPU architectures, ensuring that customers can leverage the best of AI acceleration.
- Seamless integration: Built to fit into existing Cisco UCS environments, simplifying deployment and management for enterprise IT teams.
Why NVIDIA Cloud Partner compliance matters
One of the standout aspects of the new Cisco Nexus Hyperfabric solutions is that they comply with the NCP program. But what exactly is NCP, and why is it a game-changer for organizations building AI infrastructure?
What is NVIDIA Cloud Partner compliance
NCP is a rigorous certification and best-practices program established by NVIDIA to ensure that cloud and data center infrastructure partners deliver the highest levels of performance at scale, reliability, and compatibility for AI workloads. NCP-compliant solutions are validated to work seamlessly with the NVIDIA AI stack, including GPUs, networking, and software frameworks such as NVIDIA CUDA, the CUDA Deep Neural Network library (cuDNN), and NVIDIA AI Enterprise.
NCP is important for AI Infrastructure to help provide:
- Assured compatibility: Customers can deploy Cisco Nexus Hyperfabric solutions with confidence, knowing they’ll work out of the box with NVIDIA GPUs and software stacks.
- Performance optimization: NCP compliance ensures tuning and optimizations that maximize throughput, minimize latency, and eliminate bottlenecks—critical for distributed AI training jobs.
- Enterprise support and upgrades: Businesses benefit from a streamlined support experience, with both Cisco and NVIDIA backing the solution, plus access to the latest features and enhancements.
- Faster time to value: Organizations can focus on AI innovation rather than infrastructure integration and troubleshooting.
NCP compliance positions Cisco Nexus Hyperfabric solutions as a trusted foundation for private, hybrid, and partner-hosted AI clouds, accelerating innovation while reducing deployment risk.
The Cisco–NVIDIA advantage: Transforming AI at scale
The synergy between Cisco and NVIDIA is foundational to these new solutions. Cisco brings decades of leadership in networking and data center architecture, while NVIDIA provides the acceleration technologies powering the world’s most ambitious AI projects. This combination addresses the critical challenges that organizations face as they scale up their AI initiatives, including:
- Data explosion: With more data than ever being generated, high-performance networking from Cisco ensures that data flows efficiently to where it’s needed.
- AI model complexity: As AI models grow in both size and sophistication, only tightly integrated compute and network solutions—like Cisco UCS 880/B300 and Nexus 9164E—can keep up.
- Operational intricacy: NCP compliance and automation features reduce complexity, so IT teams can focus on delivering outcomes, not managing infrastructure minutiae.
Your path to AI at scale
Our announcements at NVIDIA GTC mark a pivotal moment for AI infrastructure. Cisco Nexus Hyperfabric solutions—anchored by the Cisco UCS 880 with B300 blades and Nexus 9164E (800G) switches with NVIDIA Spectrum-4—are purpose-built for the era of AI at scale. With NVIDIA Cloud Partner compliance, these solutions set a new standard for performance, compatibility, and ease of deployment.
As you scale AI, you’ll need infrastructure that’s proven, flexible, and ready for production. Cisco Nexus Hyperfabric delivers a validated foundation for modern AI environments by uniting highperformance networking, GPUaccelerated compute, and NCPaligned architectures. The result is a platform that simplifies deployment and operations while supporting AI workloads from development through full-scale production.
AI with Nexus Hyperfabric enables two validated paths to production-grade AI infrastructure. For enterprises, Nexus Hyperfabric aligns with NVIDIA ERA compliance to deliver a secure AI factory with a full-stack, cloud-managed platform that integrates compute, NVIDIA GPUs, networking, storage, and software with deterministic performance and operational simplicity. For neocloud providers, Nexus Hyperfabric supports NCP-compliant architectures, enabling scalable GPU-as-a-service offerings that accelerate tenant onboarding, simplify lifecycle operations, and deliver predictable performance for multi-tenant AI workloads. Together, these paths provide a foundation for building and scaling AI infrastructure with confidence.
With Nexus Hyperfabric and the Cisco–NVIDIA ecosystem, you can build and scale AI with confidence. Explore Nexus Hyperfabric hands-on before you buy, at hyperfabric.cisco.com. Or get more information about the solution before you try.






: A …")




